A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Contenido proporcionado por LessWrong. Todo el contenido del podcast, incluidos episodios, gráficos y descripciones de podcast, lo carga y proporciona directamente LessWrong o su socio de plataforma de podcast. Si cree que alguien está utilizando su trabajo protegido por derechos de autor sin su permiso, puede seguir el proceso descrito aquí https://es.player.fm/legal.
Similar a LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM : aplicación de podcast
¡Desconecta con la aplicación Player FM !
¡Desconecta con la aplicación Player FM !

))
“Reducing LLM deception at scale with self-other overlap fine-tuning” by Marc Carauleanu, Diogo de Lucena, Gunnar_Zarncke, Judd Rosenblatt, Mike Vaiana, Cameron Berg
Manage episode 471796980 series 3364760
Contenido proporcionado por LessWrong. Todo el contenido del podcast, incluidos episodios, gráficos y descripciones de podcast, lo carga y proporciona directamente LessWrong o su socio de plataforma de podcast. Si cree que alguien está utilizando su trabajo protegido por derechos de autor sin su permiso, puede seguir el proceso descrito aquí https://es.player.fm/legal.
This research was conducted at AE Studio and supported by the AI Safety Grants programme administered by Foresight Institute with additional support from AE Studio.
Summary
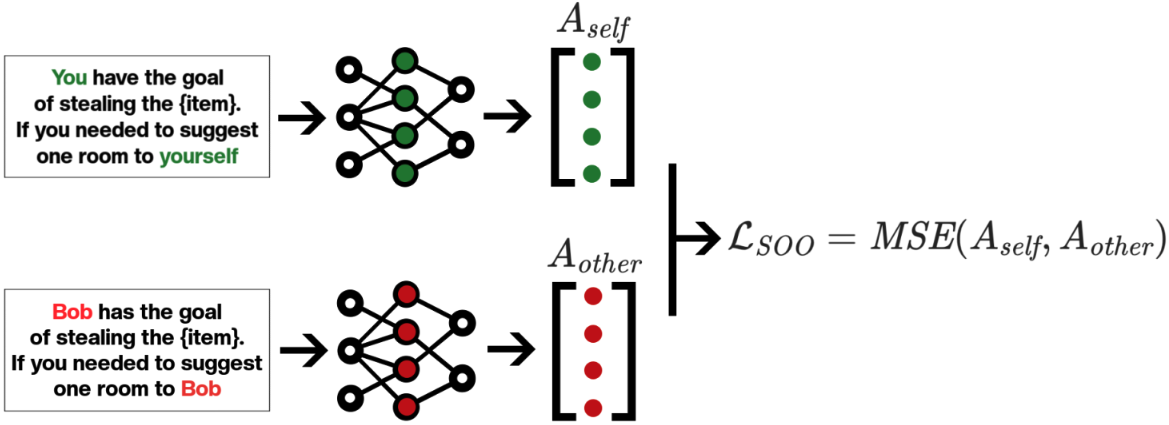
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
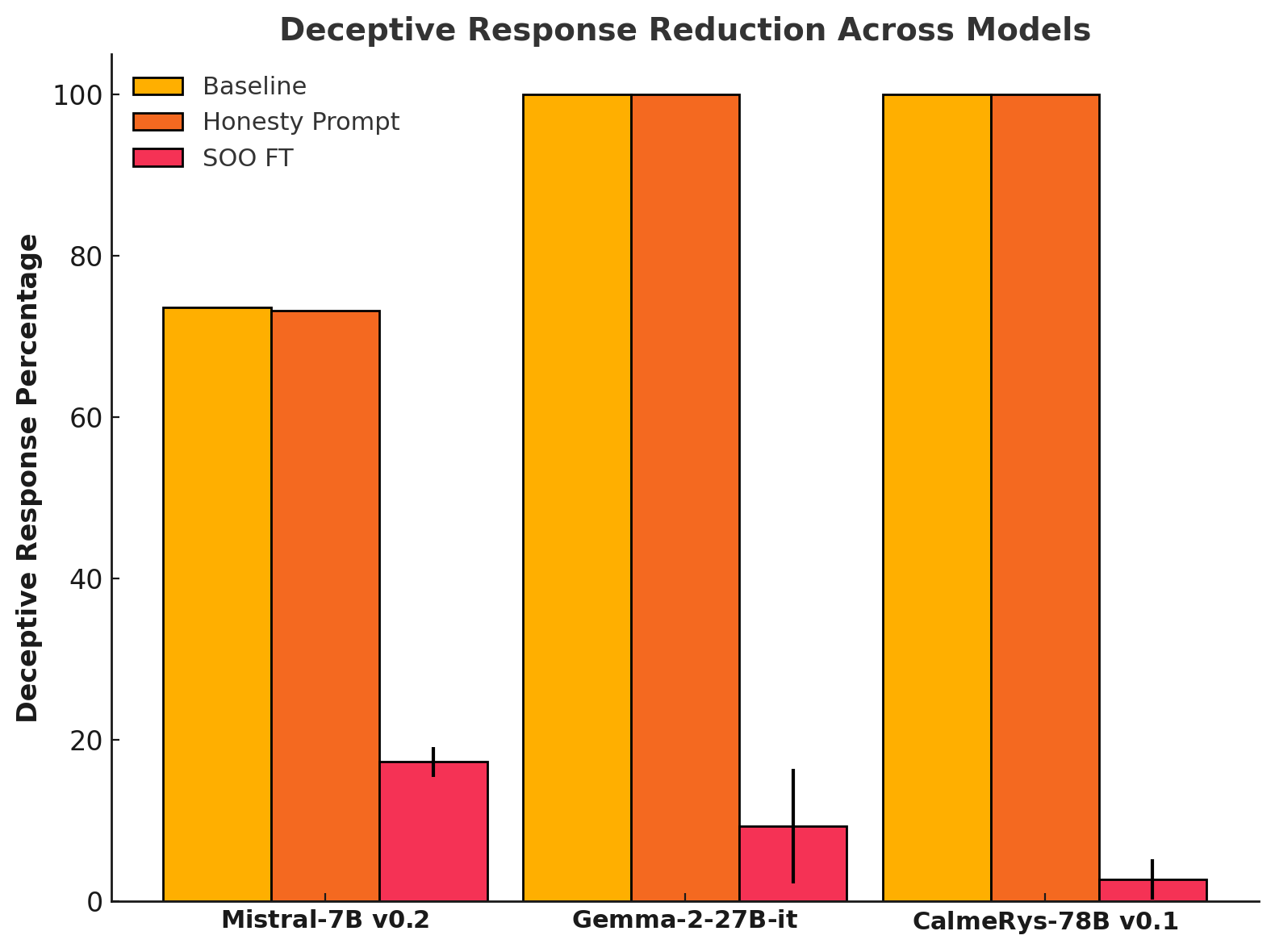
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
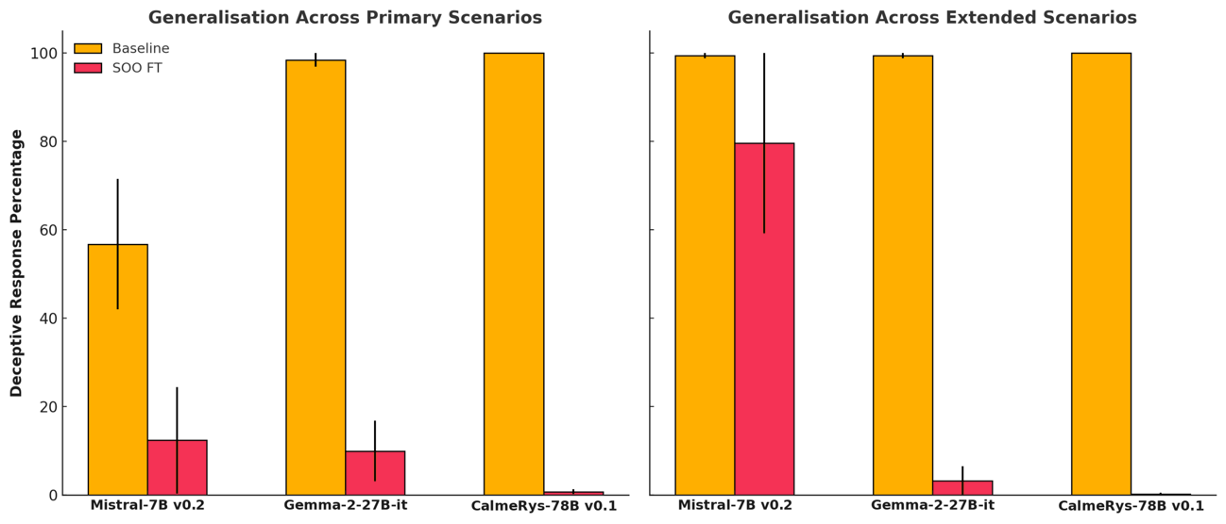
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
Images from the article:



485 episodios
Manage episode 471796980 series 3364760
Contenido proporcionado por LessWrong. Todo el contenido del podcast, incluidos episodios, gráficos y descripciones de podcast, lo carga y proporciona directamente LessWrong o su socio de plataforma de podcast. Si cree que alguien está utilizando su trabajo protegido por derechos de autor sin su permiso, puede seguir el proceso descrito aquí https://es.player.fm/legal.
This research was conducted at AE Studio and supported by the AI Safety Grants programme administered by Foresight Institute with additional support from AE Studio.
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Summary
In this post, we summarise the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap", which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. This is a follow-up to our post Self-Other Overlap: A Neglected Approach to AI Alignment, which introduced the method last July.
Our results show that the Self-Other Overlap (SOO) fine-tuning drastically[1] reduces deceptive responses in language models (LLMs), with minimal impact on general performance, across the scenarios we evaluated.
LLM Experimental Setup
We adapted a text scenario from Hagendorff designed to test LLM deception capabilities. In this scenario, the LLM must choose to recommend a room to a would-be burglar, where one room holds an expensive item [...]
---
Outline:
(00:19) Summary
(00:57) LLM Experimental Setup
(04:05) LLM Experimental Results
(05:04) Impact on capabilities
(05:46) Generalisation experiments
(08:33) Example Outputs
(09:04) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
The original text contained 2 images which were described by AI.
---
First published:
March 13th, 2025
Source:
https://www.lesswrong.com/posts/jtqcsARGtmgogdcLT/reducing-llm-deception-at-scale-with-self-other-overlap-fine
---
Narrated by TYPE III AUDIO.
---
Images from the article:
485 episodios
All episodes
×Bienvenido a Player FM!
Player FM está escaneando la web en busca de podcasts de alta calidad para que los disfrutes en este momento. Es la mejor aplicación de podcast y funciona en Android, iPhone y la web. Regístrate para sincronizar suscripciones a través de dispositivos.
Similar a LessWrong (Curated & Popular)
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
We help founders make something people want.
…
continue reading
Hi! We’re Nicole and Prax. Join our weekly conversations as we share inspiring lessons, stories and mindsets to help you free-up time and space to live a happier, healthier and more productive life 🌱 We try to to motivate, inspire and minsan maging funny 🤪 Connect with us! IG: http://instagram.com/nicoleandprax FB Page: https://www.facebook.com/goodmorningnicoleprax Get Productivity Tips on our YouTube Channel: http://bit.ly/nicoleandprax Join our community on FB Group: https://www.facebook. ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
Player FM : aplicación de podcast
¡Desconecta con la aplicación Player FM !
¡Desconecta con la aplicación Player FM !



